
Pour ce premier article sur la thématique du Deep Learning, j’ai choisi de vulgariser une sous-catégorie de réseaux de neurones artificiels, à savoir les réseaux de neurones convolutifs, également appelés réseau de neurones à convolution (en anglais Convolutional Neural Networks, CNN ou ConvNet). Il s’agit d’une méthode principalement utilisée pour le traitement d’images comme, par exemple, la détection de cancer sur des radios, la reconnaissance de piétons et de voitures pour la conduite autonome ou encore la segmentation automatique d’IRM.

Dans cette courte vidéo, on peut observer une voiture Tesla se conduire sans le recours d’un être humain. On constate que la voiture parvient parfaitement à détecter et entourer par des rectangles les autres véhicules en sus des panneaux de signalisation et des voies de circulation.
Brève histoire du Deep Learning et du CNN
Les réseaux de neurones ne datent pas d’hier ! La théorie remonte aux années 1940 avec les premiers travaux des neurologues Warren McCulloch et Walter Pitts, lesquels s’inspirent du fonctionnement du cerveau et de son mécanisme d’apprentissage. A la suite de ces travaux, le psychologue Frank Rosenblatt présente en 1957 la première machine apprenante : le réseau de neurones artificiels est né. Dès lors, la recherche dans ce domaine ne devait pas s’arrêter pour se diriger irrésistiblement vers l’Intelligence Artificielle (IA).
Avec le temps les modèles se complexifient, et par voie de conséquence sont plus performants. Les réseaux de neurones convolutifs sont inventés à la fin des années 1990 par Yann Le Cun (un français !). Avec Yoshua Bengio et Geoffrey Hinton, ils sont tous les trois considérés comme les pères du Deep Learning, terme qui se popularise vers les années 2000 avec l’arrivée de modèles toujours plus complexes.
Fonctionnement d'un réseau de neurones convolutifs
Un CNN est un type particulier de réseau de neurones constitué de plusieurs couches. Chaque couche est composée de plusieurs neurones réalisant des opérations de convolution, de padding et de pooling. A partir d’une image fournie en entrée, le CNN va chercher à détecter des formes et des contours de plus en plus précis.
Voici un exemple de réseau de neurones réalisant de la détection de visages humains. La première couche n’est capable de détecter que des formes générales comme des arcs de cercles et des lignes. La deuxième couche utilise ce que détecte la couche précédente pour reconnaitre des formes plus précises comme un nez, un œil ou une bouche. Enfin, la dernière couche combine les sorties précédentes pour reconnaître des visages :

Chaque pixel d’une image est composé de trois valeurs indiquant le niveau de bleu, de rouge et de vert. Les opérations de convolution sont réalisées sur ces matrices de valeurs.

Revenons un instant sur les neurones présents dans chaque couche. Chaque neurone d’un réseau de neurones convolutifs permet de calculer un type de contour particulier. Lorsque l’on réalise la convolution entre une image fournie en entrée de la couche et le neurone en question, la sortie produite met en évidence dans l’image le contour détecté par le neurone.
Exemple de détection de lignes verticales dans une image :

Exemple de détection de lignes horizontales dans la même image :

Plus loin dans la technique du CNN : la descente de gradient
Allons voir ce qu’il se cache plus en détails au cœur du réseau de neurones. Comme évoqué plus haut, un CNN est composé de plusieurs neurones lesquels sont à leur tour constitués de plusieurs paramètres.
Du reste, un réseau de neurones convolutifs peut posséder, sinon quelques millions, du moins quelques milliers de paramètres. Tout l’enjeu de l’apprentissage réside dans la recherche des meilleurs paramètres.
Pour ce faire, on utilise une fonction de coût. Cette fonction calcule l’équivalent d’une moyenne des différences entre les classes observées dans le jeu d’images et les classes prédites par le modèle pour un ensemble de paramètres donnés. Plus la fonction de coût se rapproche de 0, plus les valeurs prédites sont proches des valeurs observées, meilleur est le modèle. A l’inverse, plus la fonction de coût est élevée, plus les valeurs prédites sont éloignées de celles observées, moins le modèle est performant.
Exemple de fonction de coût pour un paramètre W :


Le paramètre W se met à jour de manière itérative à l’aide d’un taux d’apprentissage α strictement positif qui permet de régler la vitesse de convergence, ainsi que de la pente de la droite tangente à la courbe également appelée gradient. Le but de l’algorithme est de trouver les paramètres qui minimisent la fonction de coût. D’une certaine manière, on chercher à « descendre » dans le creux de la parabole à l’aide du gradient.
La technique du Transfer Learning
En pratique, on entraine rarement un CNN à partir de zéro. On utilise des réseaux de neurones déjà entrainés sur des milliers, sinon des millions d’images : cette technique s’appelle le Transfer Learning. Elle consiste à récupérer l’un de ces modèles, de bloquer les premières couches puisqu’elles détectent des formes générales et de ré-entrainer les couches suivantes afin d’adapter le réseau à notre problématique.
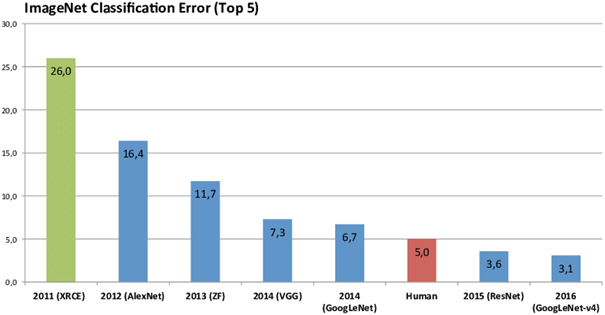
ImageNet est une base de données contenant plus de 10 millions d’images annotées à la main. Elle organise depuis 2010 un concours annuel de reconnaissance d’images parmi 1000 classes comprenant des races de chien, des oiseaux, des bateaux… En 2012 les méthodes de Deep Learning, en l’espèce les Convolutional Neural Networks, ont réalisées une véritable percée en remportant le concours avec un taux d’erreur de 16,4%.
Depuis lors, le record n’a cessé d’être battu par des modèles plus puissants mais aussi plus couteux en terme de calculs. Les temps d’entrainement pouvant atteindre plusieurs jours, le Transfer Learning est utile en ce sens qu’il permet d’obtenir des résultats similaires à plus faible coût.
Voici l’évolution du taux d’erreur au fil des années :
Conclusion
Même si la théorie derrière les réseaux de neurones convolutifs est vieille de près de 80 ans, on a réellement commencé à constater leur performance ces 10 dernières années grâce au concours organisé par ImageNet. Ces performances ont été rendues possibles grâce aux capacités de stockage de plus en plus grandes des serveurs puisque les modèles nécessitent beaucoup de données pour être performants.
Les réseaux de convolution sont de puissantes méthodes de Deep Learning permettant de réaliser du traitement d’images. Ils sont utilisés notamment en médecine pour la détection de cancer sur des IRM et des radios mais également pour la conduite de véhicules autonomes.
Florent L., Data Scientist chez Valeuriad
Bibliographie :
Quand la machine apprend, Yann Le Cun, 2019
Deep Learning, Ian Goodfellow, 2016